Reconnaissance de cartes Écosystème Savane par machine learning
En mode scoring, chaque joueur ressaisit sa grille de 20 cartes une par une. Cinq colonnes, quatre lignes, onze types d’animaux possibles. Quand on enchaîne les parties en famille, ça finit par peser. Mon fils a eu l’idée évidente : « Et si on prenait juste une photo de la grille ? »
L’objectif était simple : photographier les 20 cartes posées sur la table, et laisser l’application reconnaître chaque carte automatiquement. Simple à formuler. Nettement moins simple à réaliser.

Premier essai : tout côté client
La première approche tenait en un seul fichier JavaScript. L’idée : extraire des features de couleur et de texture pour chaque cellule de la grille, puis comparer avec des images de référence.
Concrètement, pour chaque carte photographiée, l’algorithme calculait :
- des ratios de canaux RGB (proportion de bleu, de vert, de brun…)
- un histogramme de teintes simplifié
- une mesure de densité de contours (edge density) via un filtre Sobel
- le tout comparé aux features de référence extraites des images du jeu
Le résultat : environ 60% de précision. Suffisant pour impressionner pendant 30 secondes, insuffisant pour être utile. Les confusions typiques : Eau et Gazelle (dominantes bleues/vertes proches), Guépard et Girafe (motifs tachetés similaires), et à peu près tout se mélangeait dès que l’éclairage changeait un peu.
L’algo client reste dans le code comme fallback — on y reviendra — mais il fallait passer à autre chose.
La contrainte : pas d’API externe
La solution évidente serait d’envoyer les images à Google Vision, AWS Rekognition, ou n’importe quel service cloud de classification d’images. Résultat garanti en quelques lignes de code.
Mais ce n’était pas une option. L’application tourne sur un hébergement maison. Les données restent chez nous. Pas d’abonnement à un service tiers, pas de dépendance à une API qui peut changer ses tarifs ou ses conditions du jour au lendemain. Et surtout, c’est un projet père-fils : on voulait comprendre comment ça marche, pas juste consommer une boîte noire.
Il fallait donc construire notre propre service de reconnaissance d’images. De zéro. Sur un petit serveur sans GPU.
L’architecture retenue
L’application tournait déjà avec deux containers Docker : un frontend Nginx et un backend Node.js/Redis. On a ajouté un troisième container : le service vision.
La stack :
- Python 3.11 + FastAPI pour l’API HTTP
- PyTorch avec MobileNetV2 pré-entraîné (ImageNet)
- OpenCV pour le traitement d’image (détection de grille, crop des cellules)
Le flux complet, du doigt sur le bouton au résultat affiché :
- Le joueur prend une photo de sa grille et ajuste le cadrage (crop interactif)
- Le JPEG est envoyé au backend Node.js (
POST /api/scan) - Le backend proxie vers le service vision (
POST /classify) - OpenCV détecte la grille et découpe les 20 cellules
- Chaque cellule passe dans MobileNetV2 → type de carte + score de confiance
- Les 20 résultats reviennent au frontend pour validation
Le tout en 400 à 500 ms. Sur un serveur sans GPU, en CPU pur.
L’entraînement
Les données
Pas de dataset existant pour les cartes d’Écosystème Savane — évidemment. Il a fallu créer le nôtre. On a photographié chaque type de carte dans différentes conditions : lumière naturelle, lumière artificielle, angles variés, avec et sans reflets.
Les photos brutes passent par un auto-crop OpenCV (card_cropper.py) qui détecte les contours de la carte et normalise le cadrage. Ça donne des images propres et centrées, même si la photo d’origine était prise de travers.
Au total : environ 200 images, réparties sur les 11 types de cartes. C’est peu. Très peu, pour du deep learning classique.
Le transfer learning à la rescousse
C’est là que MobileNetV2 pré-entraîné sur ImageNet fait toute la différence. Le modèle arrive déjà avec une compréhension générale des images : contours, textures, formes, couleurs. Il ne reste qu’à lui apprendre la dernière couche — celle qui dit « cette combinaison de features, c’est une Gazelle ».
En pratique :
- On gèle les 14 premières couches de features (elles restent telles qu’ImageNet les a apprises)
- On ne fine-tune que les dernières couches + un nouveau classifier (Dropout 0.3 → Linear 1280 → 11 classes)
- Learning rates différenciés : 10⁻³ pour le classifier, 10⁻⁵ pour les features dégelées
L’augmentation de données
Avec seulement 200 images, l’augmentation est cruciale pour éviter l’overfitting. À chaque passage d’entraînement, chaque image subit des transformations aléatoires :
- Rotation ±15°
- Variation de luminosité et contraste (±30%)
- Recadrage aléatoire (80-100% de l’image)
- Flip horizontal
- Flou gaussien léger
Ça multiplie artificiellement la diversité du dataset et rend le modèle robuste aux variations qu’il rencontrera en conditions réelles.
Le résultat
Split 80/20 stratifié, early stopping avec patience de 10 epochs. L’entraînement converge en quelques minutes sur CPU.
100% de précision sur le set de validation. Aucune confusion entre les 11 types. Le rapport de classification le confirme — precision, recall et f1-score à 1.00 pour chacune des 11 classes, sur 40 images de validation :
| Carte | Precision | Recall | F1-score | Support |
|---|---|---|---|---|
| Arbre | 1.00 | 1.00 | 1.00 | 6 |
| Eau | 1.00 | 1.00 | 1.00 | 4 |
| Éléphant | 1.00 | 1.00 | 1.00 | 5 |
| Gazelle | 1.00 | 1.00 | 1.00 | 3 |
| Girafe | 1.00 | 1.00 | 1.00 | 2 |
| Guépard | 1.00 | 1.00 | 1.00 | 7 |
| Hyène | 1.00 | 1.00 | 1.00 | 2 |
| Lion | 1.00 | 1.00 | 1.00 | 2 |
| Prairie | 1.00 | 1.00 | 1.00 | 3 |
| Vautour | 1.00 | 1.00 | 1.00 | 3 |
| Zèbre | 1.00 | 1.00 | 1.00 | 3 |

La matrice de confusion est l’outil de référence pour évaluer un classificateur. Chaque ligne représente la classe réelle, chaque colonne la prédiction du modèle. Une classification parfaite se traduit par des valeurs concentrées uniquement sur la diagonale.
C’est exactement ce qu’on obtient ici : une diagonale parfaite, zéro erreur sur les 11 types de cartes. Le modèle ne confond jamais un Guépard avec une Girafe, ni une Gazelle avec de l’Eau — les pièges classiques de l’ancien algorithme couleur.
Ce résultat est d’autant plus notable que le set de validation contient des images prises dans des conditions différentes de l’entraînement : angles de vue variés, éclairages naturel et artificiel, reflets sur les cartes. Le modèle généralise bien au-delà des exemples qu’il a vus.
De 60% à 100%
Le saut est spectaculaire :
| Algo client (JS) | Service vision (ML) | |
|---|---|---|
| Approche | Règles couleur + texture | MobileNetV2 fine-tuné |
| Précision | ~60% | 100% |
| Test | Subjectif | 6 grilles, 120 cellules |
| Temps | ~200ms (navigateur) | ~400-500ms (serveur) |
| Robustesse | Fragile (éclairage) | Stable |
Six grilles de test complètes — 120 cellules au total — reconnues sans erreur. Dans des conditions d’éclairage variées, sur différentes surfaces. Le modèle ne bronche pas.
Et si le serveur vision n’est pas disponible ? L’ancien algorithme JS prend le relais automatiquement. 60% c’est mieux que rien, et le joueur peut toujours corriger manuellement les erreurs via l’interface de validation.
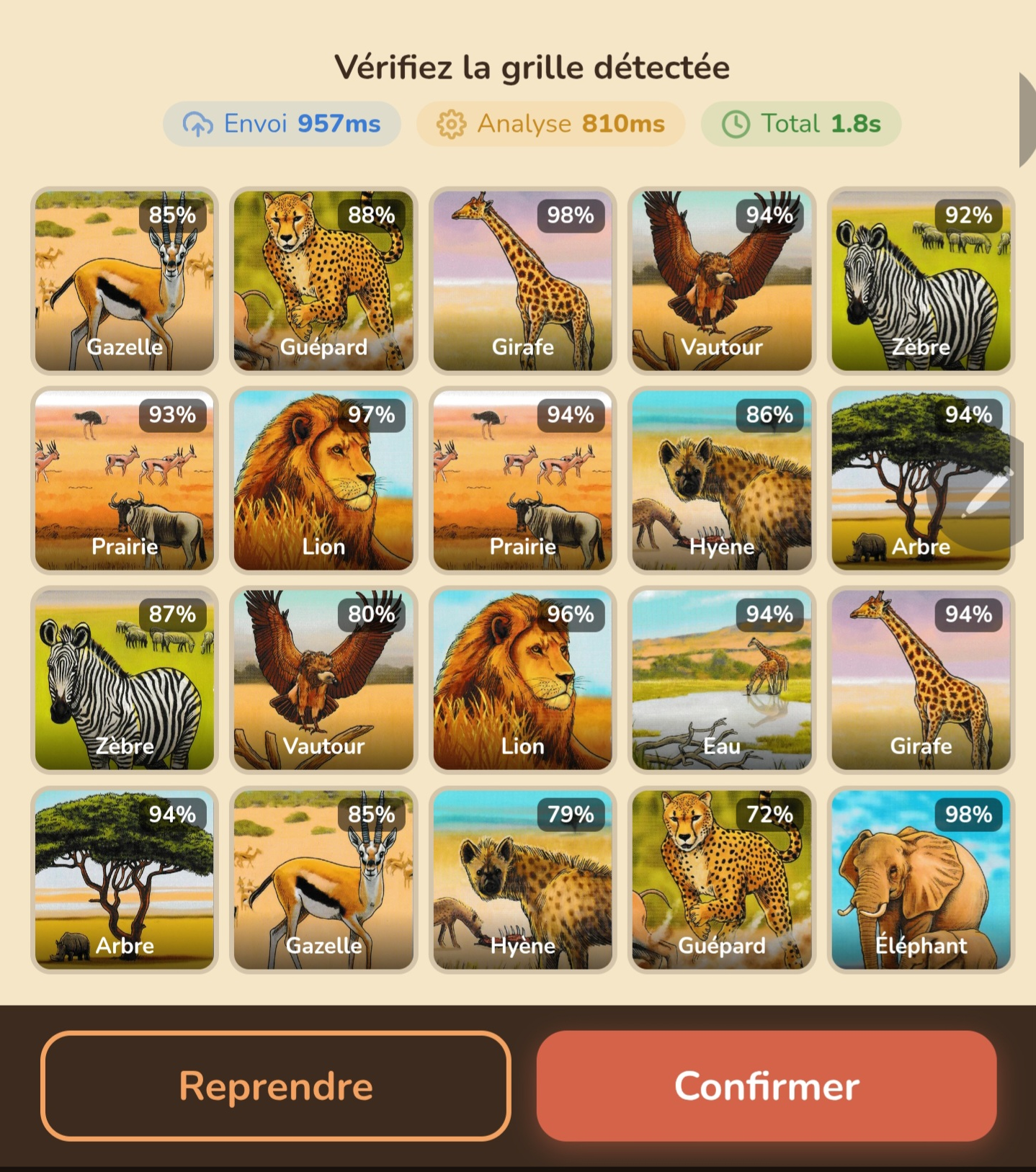
Voici ce que voit le joueur après avoir photographié sa grille : les 20 cartes sont reconnues automatiquement, chacune avec son score de confiance. Il ne reste qu’à vérifier et confirmer.
Ce qu’on a appris
Le transfer learning change la donne. Avec 200 photos et zéro GPU, on obtient un classificateur parfait pour notre cas d’usage. MobileNetV2 est suffisamment léger pour tourner en CPU sur un petit serveur, et suffisamment puissant pour distinguer 11 types de cartes sans hésiter.
L’augmentation de données est indispensable. Sans elle, le modèle apprendrait par cœur les 200 photos d’entraînement et échouerait lamentablement sur de nouvelles prises de vue.
OpenCV fait le gros du travail en amont. La détection de grille et le crop automatique sont au moins aussi importants que le modèle lui-même. Un bon preprocessing, c’est la moitié du chemin.
Le tout tourne dans un container Docker de quelques centaines de Mo, à côté du reste de l’application. Pas de cloud, pas d’abonnement, pas de données qui partent ailleurs. Juste un petit service maison qui fait exactement ce qu’on lui demande.
Le scanner photo est accessible en mode scoring — il suffit de cliquer sur l’icône appareil photo lors de la saisie de la grille.
L’accès nécessite un code d’invitation. Pour en obtenir un, contactez-moi sur Instagram :
Le jeu Écosystème Savane est édité par Origames.
Ce projet est un outil de scoring et de jeu non officiel, développé pour le plaisir — par un père et son fils qui aiment autant jouer qu’apprendre comment les choses fonctionnent.