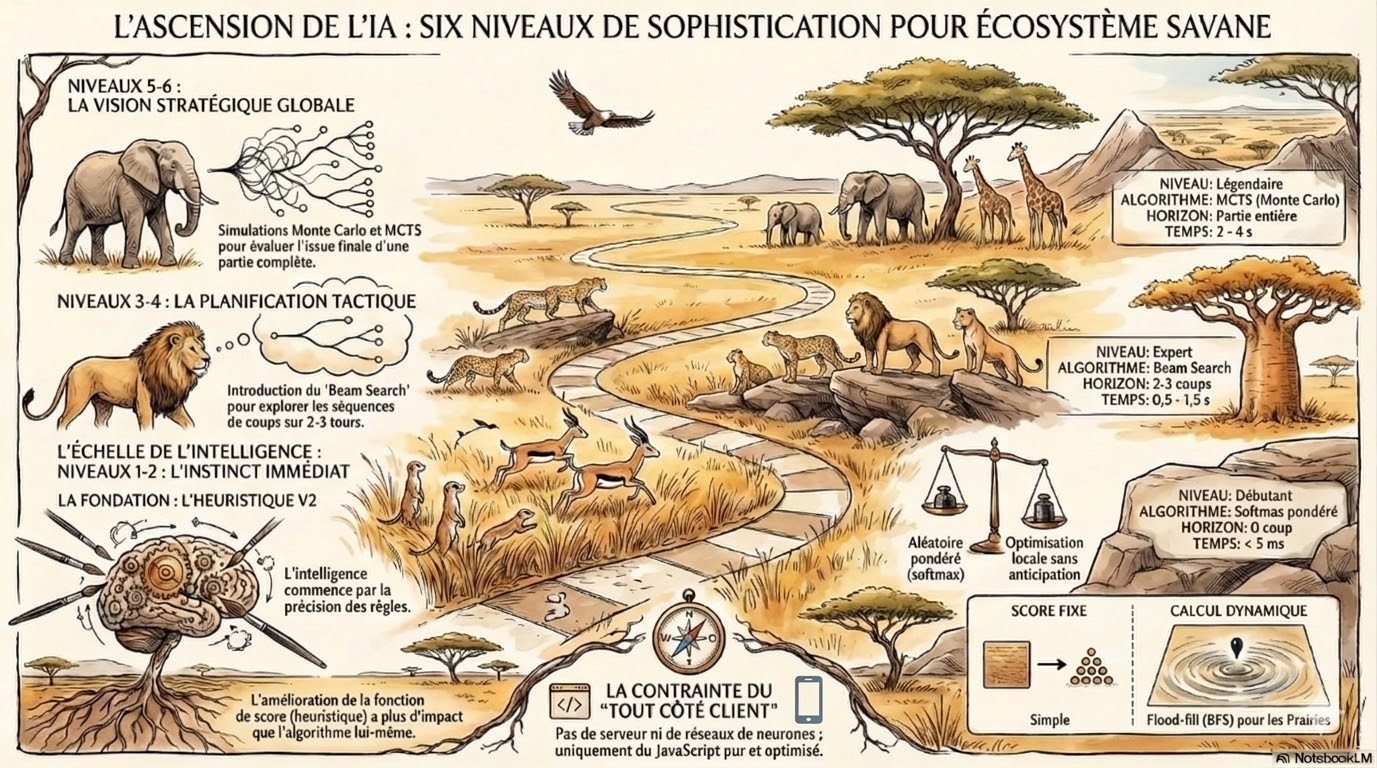
Six niveaux d'IA pour un jeu de plateau — du hasard pondéré au beam search Monte Carlo
Quand on joue à Écosystème Savane en famille, il manque parfois un joueur. Ou on veut s’entraîner seul. Ou simplement tester une stratégie sans attendre le dimanche. L’IA comble ce vide — mais encore faut-il qu’elle soit crédible à chaque niveau de jeu.
La première version avait quatre niveaux : un aléatoire pur, un greedy naïf, un échantillonneur approximatif, et un greedy exhaustif baptisé « imbattable » — qui ne l’était pas tant que ça. On a tout repris de zéro pour construire six niveaux véritablement progressifs, avec des algorithmes de plus en plus sophistiqués. Le tout tourne entièrement dans le navigateur, sans serveur, en vanilla JavaScript.

Le problème de la première IA
Les quatre anciens niveaux avaient un défaut fondamental : ils ne jouaient pas vraiment au même jeu que les humains.
Le niveau « novice » posait ses cartes au hasard — pas de logique, pas de stratégie, juste un générateur de nombres aléatoires. Le niveau « normal » utilisait une heuristique simplifiée qui ignorait la moitié des règles de scoring. L’« expert » échantillonnait arbitrairement quelques coups futurs. Et l’« imbattable » se contentait de maximiser le gain immédiat sans jamais anticiper.
Concrètement :
- L’Éléphant ne pouvait jamais avoir un score négatif (alors qu’il le peut dans les vraies règles)
- L’Arbre rapportait toujours 3 points au lieu de dépendre des lignes et colonnes couvertes
- La Hyène et le Vautour valaient systématiquement 0 en heuristique
- Le Lion IA choisissait toujours la première cible de la liste, sans réfléchir
- Personne ne tenait compte du bonus troupeau Gazelle
Résultat : même le niveau maximum était prévisible, et un joueur un peu expérimenté le battait sans effort.
La contrainte : tout côté client, en moins de 5 secondes
Pas question d’envoyer l’état de la partie à un serveur pour calculer le coup. L’IA doit tourner intégralement dans le navigateur, y compris sur un smartphone d’entrée de gamme. Budget temps : 3 à 5 secondes maximum pour les niveaux les plus lourds.
Cette contrainte élimine d’emblée les approches classiques du jeu vidéo — pas de réseau de neurones embarqué, pas de tables de transposition de plusieurs gigaoctets. Il faut des algorithmes malins, pas des algorithmes gourmands.
L’heuristique V2 : la fondation
Avant de construire les niveaux, il fallait reprendre l’heuristique de base — cette fonction rapide qui estime la valeur d’un coup sans calculer le score complet.
L’ancienne version (heuristicScore) était pleine de raccourcis. La nouvelle (heuristicScoreV2) corrige chaque type de carte :
| Carte | Avant | Après |
|---|---|---|
| Arbre | 3 points fixes | 2 × (nouvelles lignes + colonnes couvertes) |
| Éléphant | max(6 - 2n, 0) — jamais négatif | 6 - 2n - cases_vides_adj — anticipe l’encerclement futur |
| Hyène | 0 systématique | 3 × faceDown à dist 2 + potentiel Guépard/Lion positionnel |
| Vautour | 0 systématique | 4 × faceDown en dessous + potentiel Guépard/Lion + bonus positionnel |
| Gazelle | +2 ou 0 si menacée | -2 si sur diagonale d’un Guépard, +1 bonus troupeau |
| Lion | +4 si adjacent Prairie | +4 + simulation chaîne Lion→flip→Hyène/Vautour (jusqu’à 14+ pts) |
| Guépard | 3 × gazelles diag | + bonus synergie Hyène/Vautour |
| Prairie | 1 ou 3 selon adjacence | Score réel du groupe BFS résultant |
Le changement le plus important concerne la Prairie. L’ancien algo vérifiait juste « y a-t-il une Prairie adjacente ? » et attribuait 1 ou 3 points. Le nouveau lance un vrai flood-fill BFS pour calculer la taille du groupe résultant et appliquer le barème réel : 1, 4, 9 ou 16 points.
Pour le Lion, l’ancienne heuristique retournait un bonus plat de 4 à 6 points. La V2 simule la chaîne de valeur complète : pour chaque cible retournable (Gazelle ou Zèbre), elle calcule le gain des Hyènes à distance 2 (+3 chacune) et des Vautours au-dessus dans la même colonne (+4 chacun). Un Lion bien placé peut ainsi valoir plus de 14 points d’un coup.
Pour la Hyène et le Vautour, l’ancienne heuristique renvoyait 0 — ce qui signifie que l’IA les posait n’importe où. La V2 tient compte des cartes déjà retournées face cachée et du potentiel futur : les Gazelles menacées en diagonale par un Guépard, les cibles retournables par un Lion qualifiant (adjacent à une Prairie), et un bonus positionnel pour les Vautours placés en haut de colonne — même si aucune carte n’est encore face cachée en dessous.
Pour l’Éléphant, la V2 pénalise les cases vides adjacentes — car elles seront probablement remplies par des animaux plus tard, réduisant le score. L’IA préfère donc les coins et les bords.
Les six niveaux
Niveau 1 — Débutant : l’aléatoire pondéré
L’ancien « novice » jetait ses cartes au hasard. Le résultat était absurde : des Girafes loin de tout Arbre, des Éléphants entourés d’animaux, des Prairies isolées.
Le nouveau Débutant utilise un aléatoire pondéré par softmax. Chaque coup possible est évalué par l’heuristique V2, puis les scores sont convertis en probabilités via une fonction softmax avec une température élevée (2.0).
score → exp(score / température) → normalisation → probabilité
Une température élevée « aplatit » les probabilités : les bons coups sont plus probables, mais les coups moyens restent possibles. Le Débutant fait donc des choix globalement sensés mais variés — il ne posera pas une Girafe dans un coin sans Arbre, mais il ne trouvera pas non plus la combinaison optimale.
Temps de calcul : moins de 5 ms.
Niveau 2 — Intermédiaire : le greedy corrigé
Même principe que l’ancien « normal », mais avec l’heuristique V2 corrigée. L’IA prend systématiquement le meilleur coup selon l’évaluation rapide.
La différence avec le Débutant est subtile mais réelle : zéro hasard. Chaque coup est le meilleur coup local. L’Intermédiaire ne se trompe plus sur les règles de base — il sait qu’un Éléphant isolé rapporte 6 points et qu’entouré d’animaux il peut descendre en négatif.
Temps de calcul : moins de 5 ms.
Niveau 3 — Avancé : penser un coup d’avance
Premier niveau qui va au-delà de l’instant présent. Pour chaque coup candidat, l’Avancé :
- Calcule le delta de score réel (moteur de scoring complet, pas juste l’heuristique)
- Simule le placement, puis pour chaque carte restante en main, évalue le meilleur placement futur via l’heuristique V2
- Ajoute ce bonus de potentiel pondéré à 15%
Le pré-calcul du score actuel est fait une seule fois par tour (deltaScoreFast), au lieu de recalculer la grille complète pour chaque coup candidat. Cette optimisation divise le temps de calcul par un facteur important.
Temps de calcul : 50 à 150 ms.
Niveau 4 — Expert : le beam search
L’Expert utilise un beam search — une exploration de l’arbre des coups possibles sur 2 à 3 tours d’avance, en ne gardant que les branches les plus prometteuses.
Le fonctionnement :
- Profondeur 1 : évaluer tous les coups, garder les 8 meilleurs (delta de score réel)
- Profondeur 2 : pour chaque faisceau, évaluer les coups suivants avec la main réduite, garder les 5 meilleurs
- Profondeur 3 (si le temps le permet) : top 3
Le score final est la somme des deltas sur la séquence. L’Expert ne cherche pas le meilleur coup immédiat — il cherche le meilleur début de séquence.
Temps de calcul : 500 ms à 1,5 seconde.
Niveau 5 — Maître : les simulations Monte Carlo
Le Maître change de paradigme. Au lieu d’explorer un arbre de coups, il simule des parties entières.
Pour chaque coup candidat (pré-sélection des 12 meilleurs par delta de score, enrichie de coups stratégiques) :
- Placer la carte
- Répéter 20 fois : remplir le reste de la grille en mode greedy (scoring réel + cartes aléatoires du deck restant)
- Calculer le score final complet de chaque partie simulée
- Moyenne des 20 scores = valeur estimée du coup
Le coup avec la meilleure moyenne gagne.
La pré-sélection ne se limite plus au delta de score immédiat. Le Maître force l’inclusion de coups stratégiques qui seraient autrement filtrés : un Vautour placé en rangée haute (potentiel futur élevé même si le delta immédiat est nul), un Lion adjacent à une Prairie, ou un Éléphant dans un coin. Sans ce mécanisme, ces coups à rendement différé n’étaient jamais considérés.
Ce qui change par rapport à l’Expert : le Maître évalue la qualité finale d’une grille complète, pas juste les deux ou trois prochains coups. Un placement qui semble médiocre à court terme mais qui ouvre des synergies puissantes en fin de partie sera détecté.
C’est aussi le premier niveau à avoir une conscience du troupeau Gazelle : il compte les Gazelles face visible des adversaires et ajuste la valeur de ses propres placements de Gazelle en conséquence. Le bonus troupeau (+5 pour le premier, +2 pour le deuxième) est suffisamment important pour influencer la stratégie.
Temps de calcul : 1 à 2 secondes.
Niveau 6 — Légendaire : beam search + Monte Carlo
Le premier Légendaire utilisait un MCTS pur (Monte Carlo Tree Search). Ça avait l’élégance de l’algorithme qui a rendu célèbre AlphaGo — mais en pratique, avec un budget de quelques secondes sur mobile, les 300 itérations se dispersaient trop entre les branches de l’arbre. Résultat : l’Expert et son beam search déterministe le battaient régulièrement.
On a remplacé le MCTS par une approche hybride qui combine le meilleur des deux mondes : la précision du beam search et la vision à long terme du Monte Carlo.
Phase 1 — Beam search profondeur 3 : comme l’Expert, mais plus large (10 candidats au lieu de 8, enrichis de coups stratégiques). À chaque profondeur, les meilleurs coups sont évalués par delta de score réel. Le résultat : 5 séquences finalistes avec leur score cumulé sur 3 tours.
Phase 2 — Monte Carlo pour départager : pour chaque finaliste, 40 simulations de parties complètes (heavy playouts). Le score final est une combinaison pondérée :
score = 0.6 × beam_score + 0.4 × moyenne_monte_carlo
Le beam score domine (60%) car il est déterministe et stable. Le Monte Carlo (40%) apporte la vision long terme — il détecte les synergies tardives qu’un beam search profondeur 3 ne peut pas voir.
deltaScoreFast) tant qu’il reste moins de 10 cellules vides. Le fallback heuristique n’intervient qu’en début de playout quand le nombre de combinaisons est trop élevé. Cette amélioration a fait passer le score moyen du Légendaire de ~73 à ~85 points.Le Légendaire a aussi la conscience du troupeau Gazelle, comme le Maître.
Temps de calcul : 0,5 à 1,5 seconde — plus rapide que l’ancien MCTS, et plus fort.
Le Lion IA : une intelligence ciblée
Chaque Lion adjacent à une Prairie permet au joueur de retourner face cachée une Gazelle ou un Zèbre de son choix. L’ancienne IA prenait systématiquement la première cible de la liste — autant dire au hasard.
La nouvelle IA (aiChooseLionTarget) simule chaque retournement possible et calcule le gain net :
- Gain : points Hyène supplémentaires (si la cible est à distance 2 d’une Hyène : +3), points Vautour (si un Vautour est au-dessus dans la colonne : +4)
- Perte : points que la carte retournée rapportait (Gazelle : 2 pts, Zèbre : 3 × Prairies adjacentes)
La cible qui maximise gain - perte est choisie. C’est une optimisation simple mais qui change radicalement le comportement : l’IA ne sacrifie plus une Gazelle isolée quand elle pourrait retourner un Zèbre qui ne rapporte rien, juste au-dessous d’un Vautour.
La progression en pratique
| Niveau | Algo | Horizon | Temps | Score moyen |
|---|---|---|---|---|
| Débutant | Softmax pondéré | 0 coup | < 5 ms | ~50 |
| Intermédiaire | Greedy V2 | 0 coup | < 5 ms | ~65 |
| Avancé | Delta + potentiel | 1 coup | 50-150 ms | ~72 |
| Expert | Beam search | 2-3 coups | 0,5-1 s | ~80 |
| Maître | Monte Carlo | Partie entière | 1-2 s | ~80 |
| Légendaire | Beam search + MC | 3 coups + partie | 0,5-1,5 s | ~85 |
Chaque niveau apporte une amélioration qualitative, pas juste quantitative. Le Débutant et l’Intermédiaire raisonnent sur le coup en cours. L’Avancé et l’Expert planifient sur quelques tours. Le Maître et le Légendaire évaluent des parties complètes — avec des scores qui rivalisent régulièrement avec un joueur humain expérimenté.
Ce qu’on a appris
Le scoring IA doit être fidèle au vrai jeu. Le bug le plus grave n’était pas algorithmique — c’était que fullScore(), la fonction d’évaluation utilisée par tous les niveaux ≥ 3, ignorait complètement les Lions. Elle passait lionActivatedCount: 0 au moteur de scoring, donc les Lions valaient toujours 0 points dans l’évaluation de l’IA. Conséquence en cascade : sans retournement Lion, les Hyènes et Vautours ne bénéficiaient pas non plus des cartes face cachée. La correction — simuler les Lions via computePhase1AndMutate → findQualifyingLions → aiChooseLionTarget → computePhase2 — a fait bondir les scores de tous les niveaux d’un coup.
Les heuristiques comptent plus que les algorithmes. La correction de heuristicScore en heuristicScoreV2 a eu un impact bien plus grand que le passage du greedy au beam search. Et l’ajout de la chaîne de valeur Lion→Hyène/Vautour dans l’heuristique a encore changé la donne. Une heuristique qui ignore les synergies produit des résultats médiocres, quel que soit l’algorithme qui l’utilise.
Le MCTS n’est pas toujours la réponse. La première version du Légendaire utilisait un MCTS classique — l’algorithme d’AlphaGo. Élégant en théorie, mais avec un budget de quelques secondes sur mobile et des playouts coûteux, les itérations se dispersaient trop. Un beam search profondeur 3 le battait. La solution : combiner beam search (précis, déterministe) et Monte Carlo (vision long terme) en deux phases distinctes, au lieu de tout mélanger dans un arbre MCTS.
La qualité des playouts change tout. Remplacer l’heuristique V2 par le scoring réel (deltaScoreFast) dans les simulations Monte Carlo, et trier les cartes par priorité stratégique (Éléphant et Vautour d’abord), a fait passer le Légendaire de ~73 à ~85 points de moyenne. Le playout est le cœur de toute approche Monte Carlo — s’il joue mal, l’estimation est fausse.
Le pré-filtre peut tuer les bons coups. Sélectionner les 10 meilleurs candidats par delta de score immédiat élimine les coups à rendement différé : un Vautour en haut de colonne (delta 0 maintenant, +12 plus tard), un Éléphant en coin (delta +6 comme partout, mais c’est le seul endroit où il restera à +6). La solution : forcer l’inclusion de coups stratégiques dans la liste, indépendamment de leur delta immédiat.
Le tout tient dans un seul fichier JavaScript de quelques centaines de lignes, sans dépendance, sans build, sans serveur. C’est la beauté des algorithmes classiques : ils n’ont besoin de rien d’autre qu’un peu de logique et de temps CPU.
Pour jouer contre l’IA, choisissez le mode « Local » et ajoutez un adversaire IA — les 18 personnages sont répartis sur les six niveaux de difficulté.
L’accès nécessite un code d’invitation. Pour en obtenir un, contactez-moi sur Instagram :
Le jeu Écosystème Savane est édité par Origames.
Ce projet est un outil de scoring et de jeu non officiel, développé pour le plaisir — par un père et son fils qui aiment autant jouer qu’apprendre comment les choses fonctionnent.